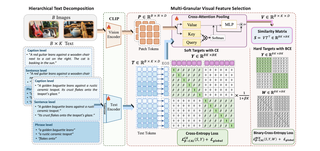
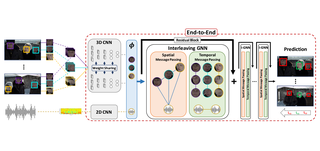
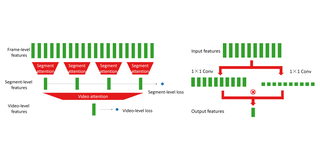
Beta-CLIP: Text-Conditioned Contrastive Learning for Multi-Granular Vision-Language AlignmentFatimah Zohra, Chen Zhao†, Hani Itani, Bernard GhanemarXiv 2026 Cite PDF
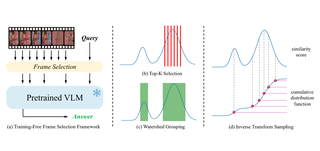
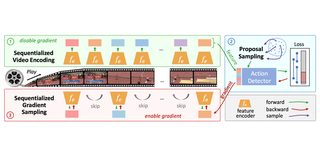
BOLT: Boost Large Vision-Language Model Without Training for Long-form Video UnderstandingShuming Liu, Chen Zhao†, Tianqi Xu, Bernard GhanemCVPR 2025 Cite Code PDF
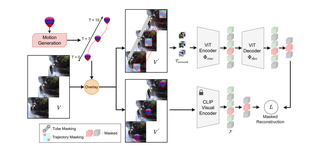
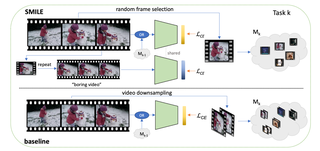
SMILE: Infusing Spatial and Motion Semantics in Masked Video LearningFida Mohammad Thoker, Letian Jiang, Chen Zhao†, Bernard GhanemCVPR 2025 Cite PDF
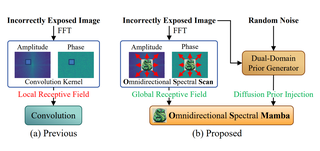
OSMamba: Omnidirectional Spectral Mamba with Dual-Domain Prior Generator for Exposure CorrectionGehui Li*, Bin Chen*, Chen Zhao†, Lei Zhang, Jian ZhangCVPR 2025 Cite PDF
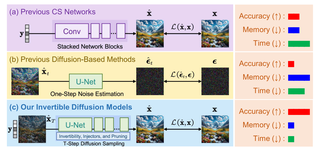
Invertible Diffusion Models for Compressed SensingBin Chen, Zhenyu Zhang, Weiqi Li, Chen Zhao†, Jiwen Yu, Shijie Zhao, Jie Chen, Jian ZhangTPAMI 2025 PDF Code Cite
SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation LearningFida Mohammad Thoker, Letian Jiang, Chen Zhao, Piyush Bagad, Hazel Doughty, Bernard Ghanem, Cees GM SnoekarXiv 2025 Cite PDF
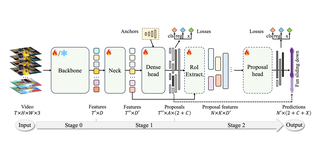
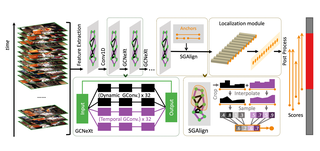
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action DetectionShuming Liu*, Chen Zhao*, Fatimah Zohra, Mattia Soldan, Alejandro Pardo, Mengmeng Xu, Lama Alssum, Merey Ramazanova, Juan León Alcázar, Anthony Cioppa, Silvio Giancola, Carlos Hinojosa, Bernard GhanemCVPRW 2025. Cite PDF
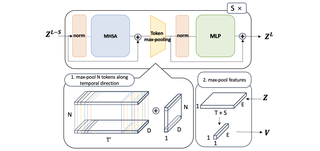
Effectiveness of Max-Pooling for Fine-Tuning CLIP on VideosFatimah Zohra, Chen Zhao, Shuming Liu, Bernard GhanemCVPRW 2025. Cite PDF
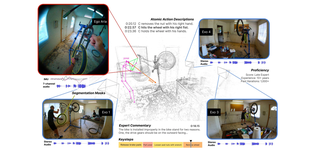
Ego4D: Around the World in 3,000 Hours of Egocentric VideoChen Zhao, with other 84 authorsTPAMI 2025. [Best Paper Nominee, Oral] Cite PDF Project
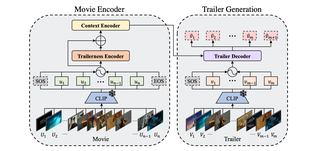
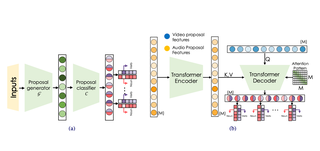
Towards Automated Movie Trailer GenerationDawit Mureja Argaw, Mattia Soldan, Alejandro Pardo, Chen Zhao†, Fabian Caba Heilbron, Joon Son Chung, Bernard GhanemCVPR 2024 Cite PDF
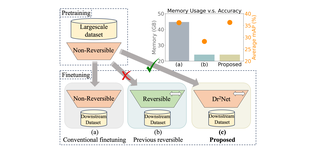
Dr2Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient FinetuningChen Zhao, Shuming Liu, Karttikeya Mangalam, Guocheng Qian, Fatimah Zohra, Abdulmohsen Alghannam, Jitendra Malik, Bernard GhanemCVPR 2024 Cite Code PDF Video
Ego-Exo4D: Understanding Skilled Human Activity from First-and Third-Person PerspectivesChen Zhao, with other 100 authorsCVPR 2024 Cite PDF Project
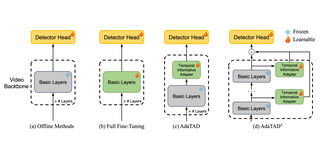
End-to-End Temporal Action Detection with 1B Parameters Across 1000 FramesShuming Liu, Chen-Lin Zhang, Chen Zhao†, Bernard GhanemCVPR 2024 Cite PDF
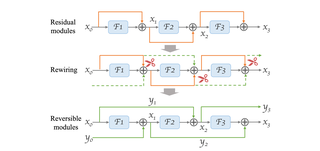
Re2TAL: Rewiring Pretrained Video Backbones for Reversible Temporal Action LocalizationChen Zhao, Shuming Liu, Karttikeya Mangalam, Bernard GhanemCVPR 2023 Cite Code PDF Video
FreeDoM: Training-Free Energy-Guided Conditional Diffusion ModelJiwen Yu, Yinhuai Wang, Chen Zhao†, Bernard Ghanem, Jian Zhang†ICCV 2023 Cite PDF
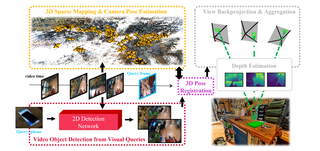
EgoLoc: Revisiting 3D Object Localization from Egocentric Videos with Visual QueriesJinjie Mai, Abdullah Hamdi, Silvio Giancola, Chen Zhao, Bernard GhanemICCV 2023. [Won the first place in Ego4D VQ3D Challenge 2023, Oral] Cite PDF
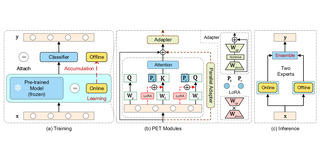
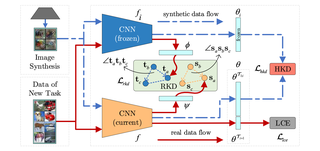
A Unified Continual Learning Framework with General Parameter-Efficient TuningQiankun Gao, Chen Zhao†, Yifan Sun, Teng Xi, Gang Zhang, Bernard Ghanem, Jian Zhang†ICCV 2023 Cite PDF
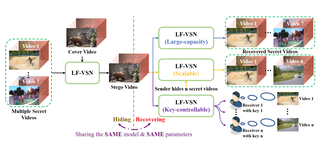
Large-capacity and Flexible Video Steganography via Invertible Neural NetworkChong Mou, Youmin Xu, Jiechong Song, Chen Zhao, Bernard Ghanem, Jian ZhangCVPR 2023 Cite Code PDF
ETAD: Training Action Detection End to End on a LaptopShuming Liu, Mengmeng Xu, Chen Zhao, Xu Zhao, Bernard GhanemCVPRW 2023. [Oral] Cite PDF
Owl (observe, watch, listen): Localizing actions in egocentric video via audiovisual temporal contextMerey Ramazanova, Victor Escorcia, Fabian Caba Heilbron, Chen Zhao, Bernard GhanemCVPRW 2023 Cite PDF
Just a Glimpse: Rethinking Temporal Information for Video Continual LearningLama Alssum, Juan Leo ́n Alca ́zar, Merey Ramazanova, Chen Zhao, Bernard GhanemCVPRW 2023. [Best Paper Award, Oral] Cite PDF
R-DFCIL: Relation-Guided Representation Learning for Data-Free Class Incremental LearningQiankun Gao, Chen Zhao, Bernard Ghanem, Jian ZhangECCV 2022 Cite Code PDF
End-to-End Active Speaker DetectionJuan Leon Alcazar, Moritz Cordes, Chen Zhao, Bernard GhanemECCV 2022 Cite Code PDF
Evaluation of Diverse Convolutional Neural Networks and Training Strategies for Wheat Leaf Disease Identification with Field-Acquired PhotographsJiale Jiang, Haiyan Liu, Chen Zhao, Can He, Jifeng Ma, Tao Cheng, Yan Zhu, Weixing Cao, Xia YaoRemote Sensing 2022 Cite PDF
When NAS Meets Trees: An Efficient Algorithm for Neural Architecture SearchGuocheng Qian, Xuanyang Zhang, Guohao Li, Chen Zhao, Yukang Chen, Xiangyu Zhang, Bernard Ghanem, Jian SunCVPRW 2022 Cite PDF
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio DescriptionsMattia Soldan, Alejandro Pardo, Juan León Alcázar, Fabian Caba Heilbron, Chen Zhao, Silvio Giancola, Bernard GhanemCVPR 2022 Cite PDF Project
Ego4D: Around the World in 3,000 Hours of Egocentric VideoChen Zhao*, with other 84 authorsCVPR 2022. [Best Paper Nomination, Oral] Cite PDF Project
SegTAD: Precise Temporal Action Detection via Semantic SegmentationChen Zhao, Merey Ramazanova, Mengmeng Xu, Bernard GhanemECCVW 2022 Cite PDF Video
Video Self‑Stitching Graph Network for Temporal Action LocalizationChen Zhao, Ali Thabet, Bernard GhanemICCV 2021 Cite Code PDF Video
ThumbNet: One Thumbnail Image Contains All You Need for RecognitionChen Zhao, Bernard GhanemACM MM 2020 Cite PDF Video
Improve Baseline for Temporal Action Detection: HACS Challenge 2020 Solution of IVUL‑KAUST teamMengmeng Xu, Chen Zhao, Merey Ramazanova, David S. Rojas, Ali Thabet, Bernard GhanemCVPRW 2020 Cite PDF
G‑TAD: Sub‑Graph Localization for Temporal Action DetectionMengmeng Xu, Chen Zhao, David Rojas Blanco, Ali Thabet, Bernard GhanemCVPR 2020 Cite Code PDF Project Slides Video
Optimization‑Inspired Compact Deep Compressive SensingJian Zhang, Chen Zhao, Wen GaoJSTSP 2020 Cite Code PDF Project
Logistic Regression is Still Alive and Effective: The 3rd YouTube 8M Challenge Solution of the IVUL‑KAUST teamMerey Ramazanova, Chen Zhao, Mengmeng Xu, Humam Alwassel, Sara Rojas Martinez, Fabian Caba, Bernard GhanemICCVW 2019 Cite PDF
CREAM: CNN-REgularized ADMM framework for compressive-sensed image reconstructionChen Zhao, Jian Zhang, Ronggang Wang, Wen GaoIEEE Access 2018 Cite PDF
BoostNet: A Structured Deep Recursive Network to Boost Image DeblockingChen Zhao, Jian Zhang, Ronggang Wang, Wen GaoVCIP 2018. [Oral] Cite PDF
Better and Faster, when ADMM Meets CNN: Compressive-sensed Image ReconstructionChen Zhao, Ronggang Wang, and Wen GaoPCM 2017. [Oral] Cite PDF
Reducing Image Compression Artifacts by Structural Sparse Representation and Quantization Constraint PriorChen Zhao, Jian Zhang, Siwei Ma, Xiaopeng Fan, Yongbing Zhang, Wen GaoTCSVT 2017 Cite Code PDF
Video Compressive Sensing Reconstruction via Reweighted Residual SparsityChen Zhao, Siwei Ma, Jian Zhang, Ruiqin Xiong and Wen GaoTCSVT 2017 Cite Code PDF
CONCOLOR: COnstrained Non-Convex Low-Rank Model for Image DeblockingJian Zhang, Ruiqin Xiong, Chen Zhao, Yongbing Zhang, Siwei Ma, Wen GaoTIP 2016 Cite Code PDF
Nonconvex Lp Nuclear Norm based ADMM Framework for Compressive SensingChen Zhao, Jian Zhang, Siwei Ma and Wen GaoDCC 2016. [Oral (acceptance rate < 10%)] Cite PDF
Compressive-Sensed Image Coding via Stripe-based DPCMChen Zhao, Jian Zhang, Siwei Ma and Wen GaoDCC 2016. [Oral (acceptance rate < 10%)] Cite PDF
A Dual Structured-Sparsity Model for Compressive-Sensed Video ReconstructionChen Zhao, Jian Zhang, Siwei Ma, Ruiqin Xiong, Wen GaoVCIP 2015. [Oral] Cite PDF
基于云数据的高效图像编码方法Chen Zhao, 马思伟, 张新峰, 张健, 高文计算机学报 2016. [Recommended from NCMT, Best Paper Award in NCMT] Cite PDF
Thousand to one: An image compression system via cloud searchChen Zhao, Siwei Ma, Wen GaoMMSP 2015 Cite PDF
Adaptive intra-refresh for low-delay error-resilient video codingHaoming Chen, Chen Zhao, Ming-Ting Sun and Aaron DrakeJVCIR 2015 Cite PDF
Video Compressive Sensing via Structured Laplacian ModellingChen Zhao, Siwei Ma, Wen GaoVCIP 2014. [Oral] Cite PDF
Image Compressive-Sensing Recovery Using Structured Laplacian Sparsity in DCT Domain and Multi-Hypothesis PredictionChen Zhao, Siwei Ma, Wen GaoICME 2014 Cite PDF
Image Compressive Sensing Recovery Using Adaptively Learned Sparsifying Basis via L0 MinimizationJian Zhang, Chen Zhao, Debin Zhao, Wen GaoSP 2014 Cite Code PDF
Weakly Supervised Photo CroppingLuming Zhang, Mingli Song, Yi Yang, Qi Zhao, Chen Zhao, Nicu SebeTMM 2014 Cite PDF
Wavelet Inpainting Driven Image Compression via Collaborative Sparsity at Low Bit RatesChen Zhao, Jian Zhang, Siwei Ma and Wen GaoICIP 2013. [Oral] Cite PDF
A Highly Effective Error Concealment Method for Whole Frame LossChen Zhao, Siwei Ma, Jian Zhang, Wen GaoISCAS 2013. [Oral] Cite PDF