End-to-End Active Speaker Detection
Abstract
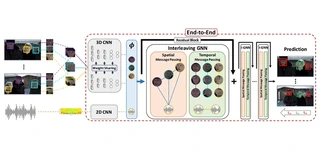
Recent advances in the Active Speaker Detection (ASD) problem build upon a two-stage process – feature extraction and spatio-temporal context aggregation. In this paper, we propose an end-to-end ASD workflow where feature learning and contextual predictions are jointly learned. Our end-to-end trainable network simultaneously learns multi-modal embeddings and aggregates spatio-temporal context. This results in more suitable feature representations and improved performance in the ASD task. We also introduce interleaved graph neural network (iGNN) blocks, which split the message passing according to the main sources of context in the ASD problem. Experiments show that the aggregated features from the iGNN blocks are more suitable for ASD, resulting in state-of-the art performance. Finally, we design a weakly-supervised strategy, which demonstrates that the ASD problem can also be approached by utilizing audiovisual data but relying exclusively on audio annotations. We achieve this by modelling the direct relationship between the audio signal and the possible sound sources (speakers), as well as introducing a contrastive loss.
Type
Publication
European Conference on Computer Vision (ECCV), 2022
