ETAD: Training Action Detection End to End on a Laptop
June 2, 2023·
, ,,·
0 min read
,,·
0 min read
Shuming liu
Mengmeng xu
Chen Zhao
Xu zhao
Bernard ghanem
Abstract
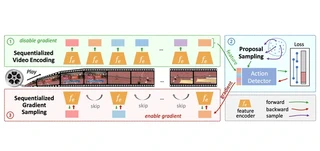
Untrimmed video understanding such as temporal action detection (TAD) often suffers from the pain of huge demand for computing resources. Because of long video durations and limited GPU memory, most action detectors can only operate on pre-extracted features rather than the original videos, and they still require a lot of computation to achieve high detection performance. To alleviate the heavy computation problem in TAD, in this work, we first propose an efficient action detector with detector proposal sampling, based on the observation that performance saturates at a small number of proposals. This detector is designed with several important techniques, such as LSTM-boosted temporal aggregation and cascaded proposal refinement to achieve high detection quality as well as low computational cost. To enable joint optimization of this action detector and the feature encoder, we also propose encoder gradient sampling, which selectively back-propagates through video snippets and tremendously reduces GPU memory consumption. With the two sampling strategies and the effective detector, we build a unified framework for efficient end-to-end temporal action detection (ETAD), making real-world untrimmed video understanding tractable. ETAD achieves state-of-the-art performance on both THUMOS-14 and ActivityNet-1.3. Interestingly, on ActivityNet-1.3, it reaches 37.78% average mAP, while only requiring 6 mins of training time and 1.23 GB memory based on pre-extracted features. With end-to-end training, it reduces the GPU memory footprint by more than 70% with even higher performance (38.21% average mAP), as compared with traditional end-to-end methods.
Type
Publication
IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2023. [Oral]
