Owl (observe, watch, listen): Localizing actions in egocentric video via audiovisual temporal context
June 1, 2023·
,, ,·
0 min read
,·
0 min read
Merey ramazanova
Victor escorcia
Fabian caba heilbron
Chen Zhao
Bernard ghanem
Abstract
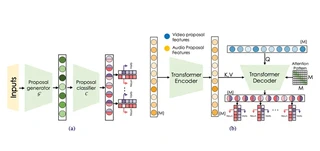
Temporal action localization (TAL) is an important task extensively explored and improved for third-person videos in recent years. Recent efforts have been made to perform fine-grained temporal localization on first-person videos. However, current TAL methods only use visual signals, neglecting the audio modality that exists in most videos and that shows meaningful action information in egocentric videos. In this work, we take a deep look into the effectiveness of audio in detecting actions in egocentric videos and introduce a simple-yet-effective approach via Observing, Watching, and Listening (OWL) to leverage audio-visual information and context for egocentric TAL. For doing that, we 1) compare and study different strategies for where and how to fuse the two modalities; 2) propose a transformer-based model to incorporate temporal audio-visual context. Our experiments show that our approach achieves state-of-the-art performance on EPIC-KITCHENS-100.
Type
Publication
IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2023
