SegTAD: Precise Temporal Action Detection via Semantic Segmentation
Abstract
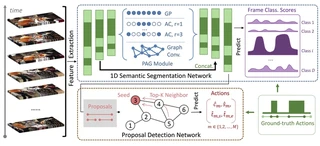
Temporal action detection (TAD) is an important yet challenging task in video analysis. Most existing works draw inspiration from image object detection and tend to reformulate it as a proposal generation - classification problem. However, there are two caveats with this paradigm. First, proposals are not equipped with annotated labels, which have to be empirically compiled, thus the information in the annotations is not necessarily precisely employed in the model training process. Second, there are large variations in the temporal scale of actions, and neglecting this fact may lead to deficient representation in the video features. To address these issues and precisely model temporal action detection, we formulate the task of temporal action detection in a novel perspective of semantic segmentation. Owing to the 1-dimensional property of TAD, we are able to convert the coarse-grained detection annotations to fine-grained semantic segmentation annotations for free. We take advantage of them to provide precise supervision so as to mitigate the impact induced by the imprecise proposal labels. We propose an end-to-end framework SegTAD composed of a 1D semantic segmentation network (1D-SSN) and a proposal detection network (PDN).
Type
Publication
European Conference on Computer Vision Workshop (ECCVW), 2022
